



Hasura Cloud Changelog¶
Table of contents
Introduction¶
Please find the changelog (includes features, bug fixes, breaking change notifications, etc) of Hasura Cloud versions here.
v2.0.0-cloud.11¶
Server: Fix erroneous schema type for action output fields (fix #6631)
Server: Introduce
HASURA_GRAPHQL_GRACEFUL_SHUTDOWN_TIMEOUTenv var for server config. This configures the time (default: 60s) to wait for any in-flight scheduled events, event trigger events and async actions to complete before shutting down. After this time, any in-flight events will be marked as pending.Server: Fix a regression from V1 and allow string values for most Postgres column types
Server: Sanitise event trigger and scheduled trigger logs to omit possibly sensitive request body and headers
Server: Fix parsing of values for Postgres char columns (fix #6814)
Server: Explaining/analyzing a query now works for mssql sources
Server: Fix MSSQL multiplexed subscriptions (fix #6887)
Server: Fix bug which prevented tables with the same name in different sources to be tracked after setting custom names
Server: Include more detail in inconsistent metadata error messages (fix #6684)
Server: Add node limits for GraphQL operations
Console: Add union types to remote schema permissions
CLI: Add
-o/--outputflag for metadataapply&exportsubcommands# export metadata and write to stdout $ hasura metadata export -o json
CLI: Add support for
graphql_schema_introspectionmetadata objectCLI: Fix applying migrations in a different environment after config v3 update (#6861)
CLI: Fix bug caused by usage of space character in database name (#6852)
CLI: Fix issues with generated filepaths in windows (#6813)
v2.0.0-cloud.10¶
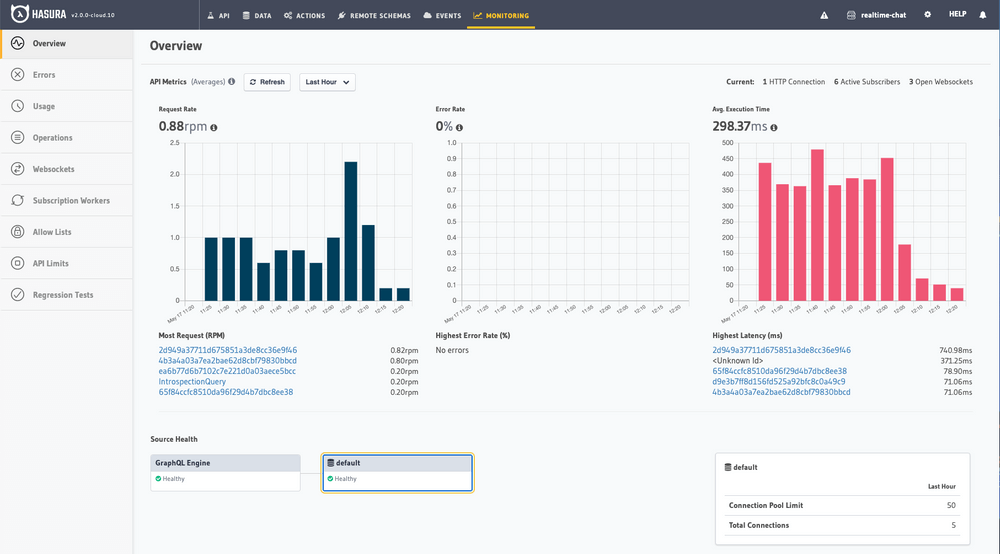
New Overview page for Monitoring¶
The new Overview page gives a birds eye view of current load, historical API performance, source health and associated metrics.
- Server: Fix MSSQL table metadata SQL, return empty array for empty rows (fix #1226)
- Server: Aggregation fields are now supported on mssql
- Server: restore proper batching behavior in event trigger processing so that at most 2x batch events are checked out at a time
- Server: Fix regression
on_conflictwas missing in the schema for inserts in tables where the current user has no columns listed in their update permissions (fix #6804) - Server: Fix one-to-one relationship bug which prevented adding one-to-one relationships which didn’t have the same column name for target and source
- Server: Fix query execution of custom function containing a composite argument type
- Server: Fix a bug in query validation that would cause some queries using default variable values to be rejected (fix #6867)
- Server: Custom URI schemes are now supported in CORS config (fix #5818)
- Server: REST endpoint bugfix for UUID url params
- Server: Support disabling GraphQL introspection for specified roles
- Console: Fix Postgres table creation when table has a non-lowercase name and a comment (#6760)
- Console: Read-only modify page for mssql
- Console: Filter out partitions from track table list and display partition info
- Console: Fixes an issue where no schemas are listed on an MSSQL source
- Console: Fix missing headers in event trigger invocations page which logged out Cloud console
- CLI: Fix regression -
metadata apply —dry-runwas overwriting local metadata files with metadata on server when it should just display the differences. - CLI: Add support for api_limits metadata object
- Dashboard: Add env var
HASURA_GRAPHQL_V1_BOOLEAN_NULL_COLLAPSE(default: false)
v2.0.0-cloud.9¶
Server: All /query APIs now require admin privileges
v2.0.0-cloud.8¶
Server: Format the values of injectEventContext as hexadecimal string instead of integer (fix #6465)
v2.0.0-cloud.7¶
Support for 3D PostGIS Operators¶
We now support the use of the functions ST_3DDWithin and ST_3DIntersects in boolean expressions.
Note that ST_3DIntersects requires PostGIS be built with SFCGAL support which may depend on the PostGIS distribution used.
- Server: Format Tracing values inside trace_log to string.
- Server: Fix issue with scheduled trigger logs
v2.0.0-cloud.6¶
- Miscellaneous fixes
v2.0.0-cloud.5¶
- Console: Add request preview for REST endpoints
v2.0.0-cloud.4¶
Support for null values in boolean expressions¶
In v2, we introduced a breaking change, that aimed at fixing a long-standing issue: a null value in a boolean expression would always evaluate to True for all rows. For example, the following queries were all equivalent:
delete_users(where: {_id: {_eq: null}}) # field is null, which is as if it were omitted
delete_users(where: {_id: {}}) # object is empty, evaluates to True for all rows
delete_users(where: {}) # object is empty, evaluates to True for all rows
delete_users() # delete all users
This behaviour was unintuitive, and could be an unpleasant surprise for users that expected the first query to mean “delete all users for whom the id column is null”. Therefore in v2, we changed the implementation of boolean operators to reject null values, as we deemed it safer:
delete_users(where: {_id: {_eq: null}}) # error: argument of _eq cannot be null
However, this change broke the workflows of [some of our users](https://github.com/hasura/graphql-engine/issues/6660) who were relying on this property of boolean operators. This was used, for instance, to _conditionally_ enable a test:
query($isVerified: Boolean) {
users(where: {_isVerified: {_eq: $isVerified}}) {
name
}
}
- Console: Add custom_column_names to track_table request with replaced invalid characters
- Console: Add details button to the success notification to see inserted row
v2.0.0-cloud.3¶
Transactions for Postgres mutations¶
With v2 came the introduction of heterogeneous execution: in one query or mutation, you can target different sources: it is possible, for instance, in one mutation, to both insert a row in a table in a table on Postgres and another row in another table on MSSQL:
mutation {
# goes to Postgres
insert_author_one(object: {name: "Simon Peyton Jones"}) {
name
}
# goes to MSSQL
insert_publication_one(object: {name: "Template meta-programming for Haskell"}) {
name
}
}
However, heterogeneous execution has a cost: we can no longer run mutations as a transaction, given that each part may target a different database. This is a regression compared to v1.
While we want to fix this by offering, in the future, an explicit API that allows our users to choose when a series of mutations are executed as a transaction, for now we are introducing the following optimisation: when all the fields in a mutation target the same Postgres source, we will run them as a transaction like we would have in v1.
- Server: Add connection acquisition latency metrics for Postgres databases
- Server: Log the
parametrized_query_hashvalue inhttp-loglogs - Server: Fix a bug preventing some MSSQL foreign key relationships from being tracked
- Console: Data sidebar bug fixes and improvements
- CLI: Fix seeds incorrectly being applied to databases in config-v3
- CLI: Add
--all-databasesflag for migrate apply, this allows applying migrations on all connected databases in one go - Docs: Add Hasura v2 upgrade guide
- CI/CD: Add
cli-migrationsconfig-v3 image
v2.0.0-cloud.2¶
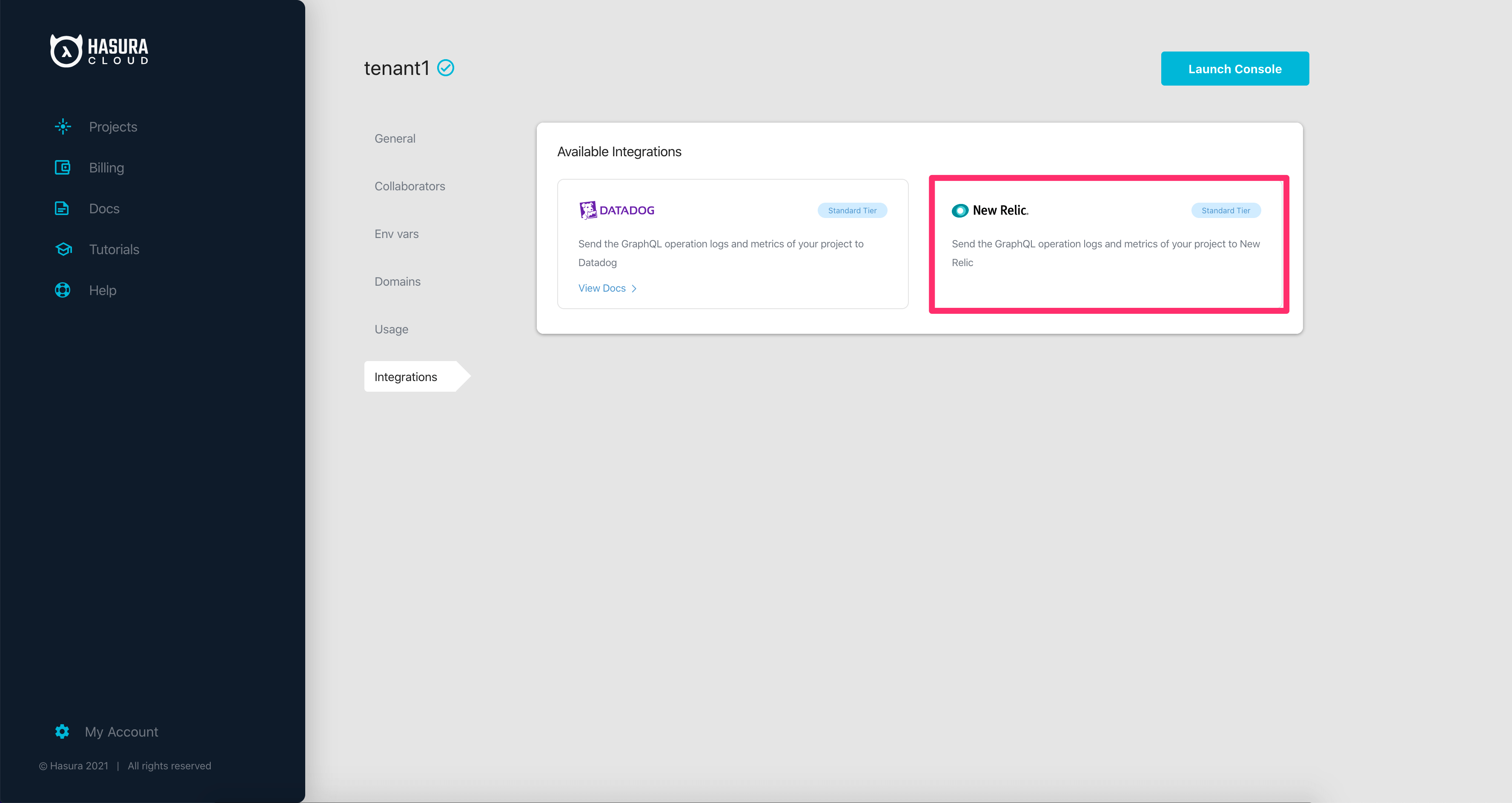
Add New Relic APM integration¶
You can now export metrics and operation logs of your Hasura Cloud project to New Relic.
- Server: Add
replace_configurationoption (default: false) in the add source API payload - Server: Add a comment field for actions
- Server: Accept GeoJSON for MSSQL geometry and geography operators
- Console: Add a comment field for actions
v2.0.0-cloud.1¶
Includes everything from OSS v2.0.0-alpha.1 through v2.0.0-alpha.6: https://github.com/hasura/graphql-engine/releases
- Hasura Cloud now stores project metadata in its own managed database
- Allow adding data source using env var
- Add cache rate limiting to the query cache.
- Support queries with session variables in @cached.
- Add endpoints for clearing the query cache and reading the query cache metrics.
- Add read replicas UI
Breaking changes¶
This version includes breaking changes from previous version (i.e v1.3.3-cloud.x).
Multiple mutations in same request are not transactional
UPDATE (since v2.0.0-cloud.3): For only Postgres data source, multiple fields in a mutation will be run in one transaction to preserve backwards compatibility.
Semantics of explicit “null” values in “where” filters have changed
According to the discussion in issue 704, an explicit
nullvalue in a comparison input object will be treated as an error rather than resulting in the expression being evaluated toTrue.For example: The mutation
delete_users(where: {id: {_eq: $userId}}) { name }will yield an error if$userIdisnullinstead of deleting all users.UPDATE (since v2.0.0-cloud.10): The old behaviour can be enabled by setting an environment variable:
HASURA_GRAPHQL_V1_BOOLEAN_NULL_COLLAPSE: true.Semantics of “null” join values in remote schema relationships have changed
In a remote schema relationship query, the remote schema will be queried when all of the joining arguments are not
nullvalues. When there arenullvalue(s), the remote schema won’t be queried and the response of the remote relationship field will benull. Earlier, the remote schema was queried with thenullvalue arguments and the response depended upon how the remote schema handled thenullarguments but as per user feedback, this behaviour was clearly not expected.Order of keys in objects passed as “order_by” operator inputs is not preserved
The
order_byoperator accepts an array of objects as input to allow ordering by multiple fields in a given order, i.e.[{field1: sortOrder}, {field2: sortOrder}]but it is also accepts a single object with multiple keys as an input, i.e.{field1: sortOrder, field2: sortOrder}. In earlier versions, Hasura’s query parsing logic used to maintain the order of keys in the input object and hence the appropriateorder byclauses with the fields in the right order were generated .As the GraphQL spec mentions that input object keys are unordered, Hasura v2.0’s new and stricter query parsing logic doesn’t maintain the order of keys in the input object taking away the guarantee of the generated
order byclauses to have the fields in the given order.For example: The query
fetch_users(order_by: {age: desc, name: asc}) {id name age}which is intended to fetch users ordered by their age and then by their name is now not guaranteed to return results first ordered by age and then by their name as theorder_byinput is passed as an object. To achieve the expected behaviour, the following queryfetch_users(order_by: [{age: desc}, {name: asc}]) {id name age}should be used which uses an array to define the order of fields to generate the appropriateorder byclause.Incompatibility with older Hasura version remote schemas
With v2.0, some of the auto-generated schema types have been extended. For example,
String_comparison_exphas an additionalregexinput object field. This means if you have a Hasura API with an older Hasura version added as a remote schema then it will have a type conflict. You should upgrade all Hasura remote schemas to avoid such type conflicts.Migrations are not executed under a single transaction
While applying multiple migrations, in earlier Hasura CLI versions all migration files were run under one transaction block. i.e. if any migration threw an error, all the previously successfully executed migrations would be rolled back. With Hasura CLI v2.0, each migration file is run in its own transaction block but all the migrations are not executed under one. i.e. if any migration throws an error, applying further migrations will be stopped but the other successfully executed migrations up till that point will not be rolled back.
 Thank you for subscribing to our newsletter!
Thank you for subscribing to our newsletter!